企业私有知识平台
Superagent
面向企业私有数据的 AI 层,把分散的文档、产品数据、工单、数据库和内部流程转成可追溯、可执行的智能问答与自动化工作流。
混合检索精排优化标准 API 接入多工具协同
365UI — 企业私有 AI 系统
Superagent 是 365UI 的旗舰平台:一套可自托管的企业知识问答与智能工作流系统,已在标普 500 企业的生产环境中实际运行,服务于对答案准确性、工作流可审计性和数据隐私有严格要求的团队。

平台
365UI 帮企业把私有知识、业务系统和日常工作流接入可控的 AI 运行时,让团队能安全地检索、分析、执行和沉淀经验。
企业私有知识平台
面向企业私有数据的 AI 层,把分散的文档、产品数据、工单、数据库和内部流程转成可追溯、可执行的智能问答与自动化工作流。
组织记忆与知识沉淀
让团队经验和决策历史像代码一样可追溯、可审计、可复用。AI 持续沉淀执行经验,人工审核后纳入正式知识库,避免重复犯错。
邮件智能助手
面向高邮件量场景的私有助手:每日要点汇总、优先级分流、附件内容理解、邮件语义搜索和回复草稿。
实时语音交互
面向家庭和边缘设备的常驻语音助手,支持提醒、环境感知、实时对话和跨系统操作。
流程自动化 Agent
将重复性专业工作转为可审计的自动化流程:代码质量修复、招聘候选人筛选、报告生成和跨系统业务操作。
模型选型与推理部署
覆盖 40+ 主流大语言模型、Embedding 和精排模型的评测对比,以及 GPU 集群上的高性能推理部署方案。
AI 协作规范
一套面向人机协同团队的项目治理标准,统一 AI 助手规则、决策记录和经验沉淀格式,防止多人多 Agent 协作中的上下文混乱。
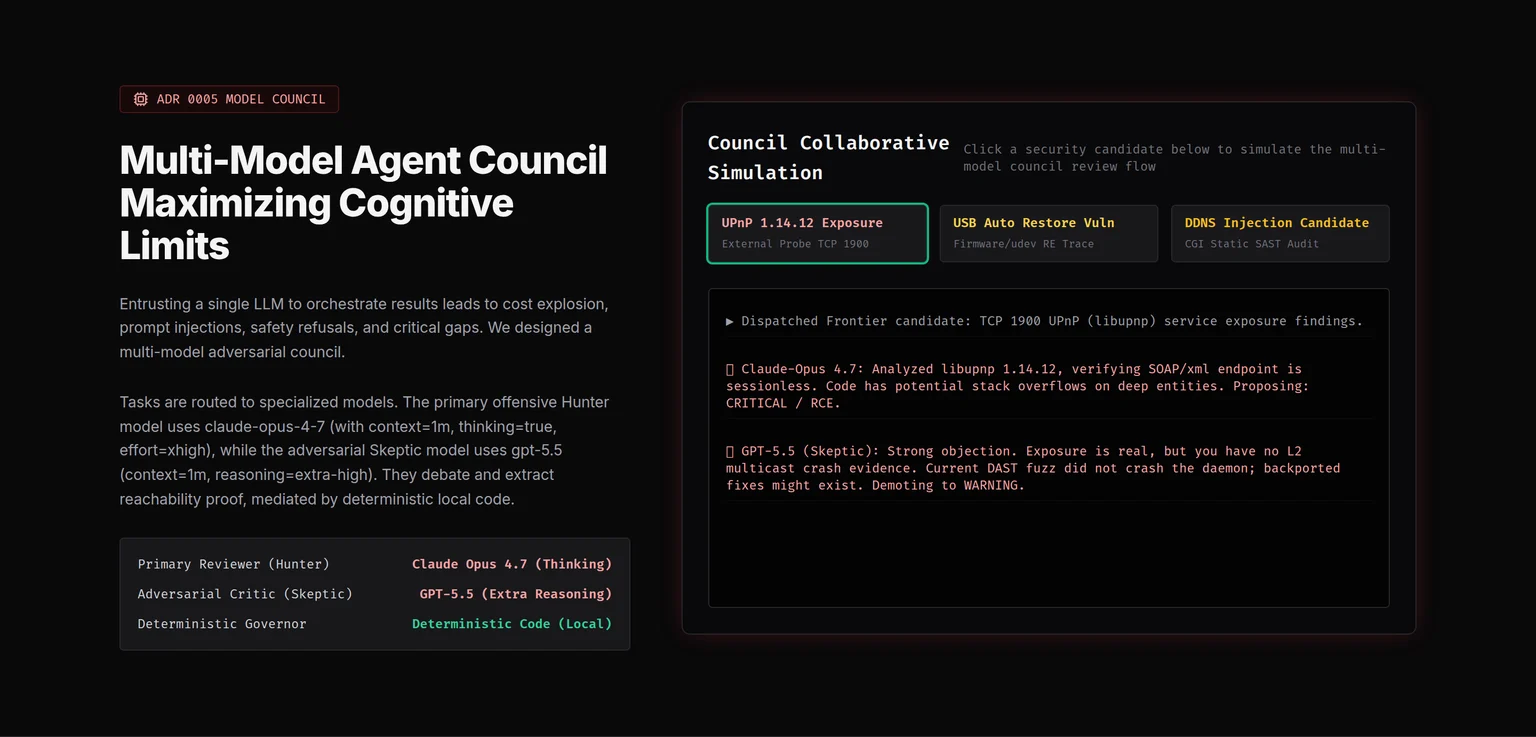
AI 原生 BMC 自主漏洞发现与验证平台
面向服务器 BMC 的 AI 红队闭环平台:232 个专项 skill 沿 7 条深度评估通道路由,由多模型 Council(Claude Opus 4.7 Hunter + GPT-5.5 Skeptic + Deterministic Governor)协同决策。所有发现按 Proof Ladder(静态候选 → daemon 可达 → 实验室复现 → 可利用性)逐级晋升,且攻防成对——每条攻击 primitive 自动起 paired Sigma 检测规则。OpenBMC `libpldm decode_get_types_resp()` 报告已由官方安全团队答复跟进。
项目证明
365UI 的每个产品都来自真实交付经验,涵盖标普 500 企业级 AI 助手平台、百万级文档检索、流程自动化、大模型推理服务、消息平台助手和边缘语音产品。
查看完整案例页最新成果 · OpenBMC 上游已答复
面向服务器 BMC 的 AI 自主漏洞发现与验证平台:232 个专项 skill 沿 7 条评估通道路由,多模型 Council 协同博弈——主审查官 Claude Opus 4.7 (Thinking)、唱反调合规官 GPT-5.5 (Extra Reasoning)、最终决策由确定性 Node 代码 Governor(Fail-Closed)下达。所有发现按 Proof Ladder 逐级晋升(静态候选 → deployed daemon 可达 → 实验室复现 → 可利用性),每条攻击 primitive 自动起 paired Sigma 检测规则。OpenBMC `libpldm decode_get_types_resp()` 报告已经从源码 OOB read 推进到 deployed pldmd 可达、受控 fake MCTP peer-path 证据与 candidate fix,并由 OpenBMC 官方安全团队答复跟进。
标普 500 企业交付
为企业交付完整的私有 AI 助手平台,覆盖多源数据采集(网页、SharePoint、PDF/Office)、多租户配置和跨行业零代码部署,目前在生产环境持续运行。
百万级文档检索
在 1M+ 向量和 778K+ 文档规模上实现高精度混合检索,融合语义检索、关键词匹配、多级精排和多跳推理,并通过 Agent 协调数据库查询、网页搜索等多种工具。
可度量的业务提升
通过检索链路、精排、上下文扩展和资源优化,将系统性能提升到生产可用水平:响应延迟从 137 秒降至 6.6 秒,数据导入速度提升 260 倍。
代码质量 + 招聘效率
面向大规模运营场景的自动化 Agent:Code-Fix Agent 自动修复 12,000+ 代码质量问题;AI Recruiter 从职位描述自动提取筛选标准,一键生成候选人短名单。
模型选型与推理部署
完成 40+ 主流大语言模型、Embedding 和精排模型的对比评测,并在 H100/H200/B300 级 GPU 集群上优化部署高性能推理服务。
多人多 Agent 协作规范
一套面向人机协同团队的治理标准,统一 AI 助手规则、架构决策记录和执行经验沉淀格式,防止多人多 Agent 协作中的规则膨胀和上下文污染。
封闭生态中的 AI 产品
在封闭消息生态中上线 AI 助手产品,支持多模态对话、意图路由、网页搜索、金融数据、深度研究、群组分析、内容审核和 API 网关。
环境智能原型
在边缘设备上部署 24/7 常驻语音助手,支持全双工实时对话、长期记忆、日程提醒、免打扰调度和摄像头环境感知。
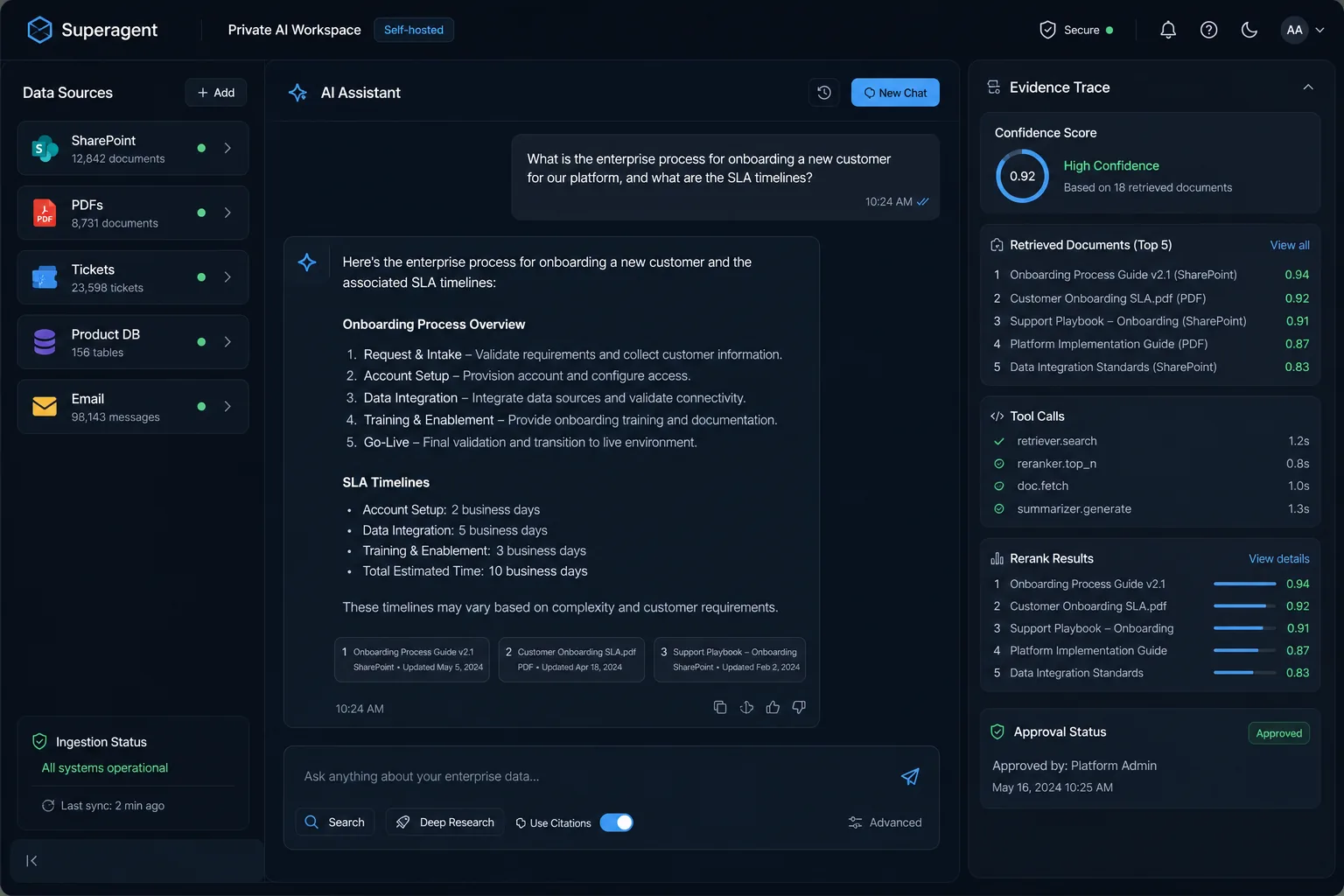
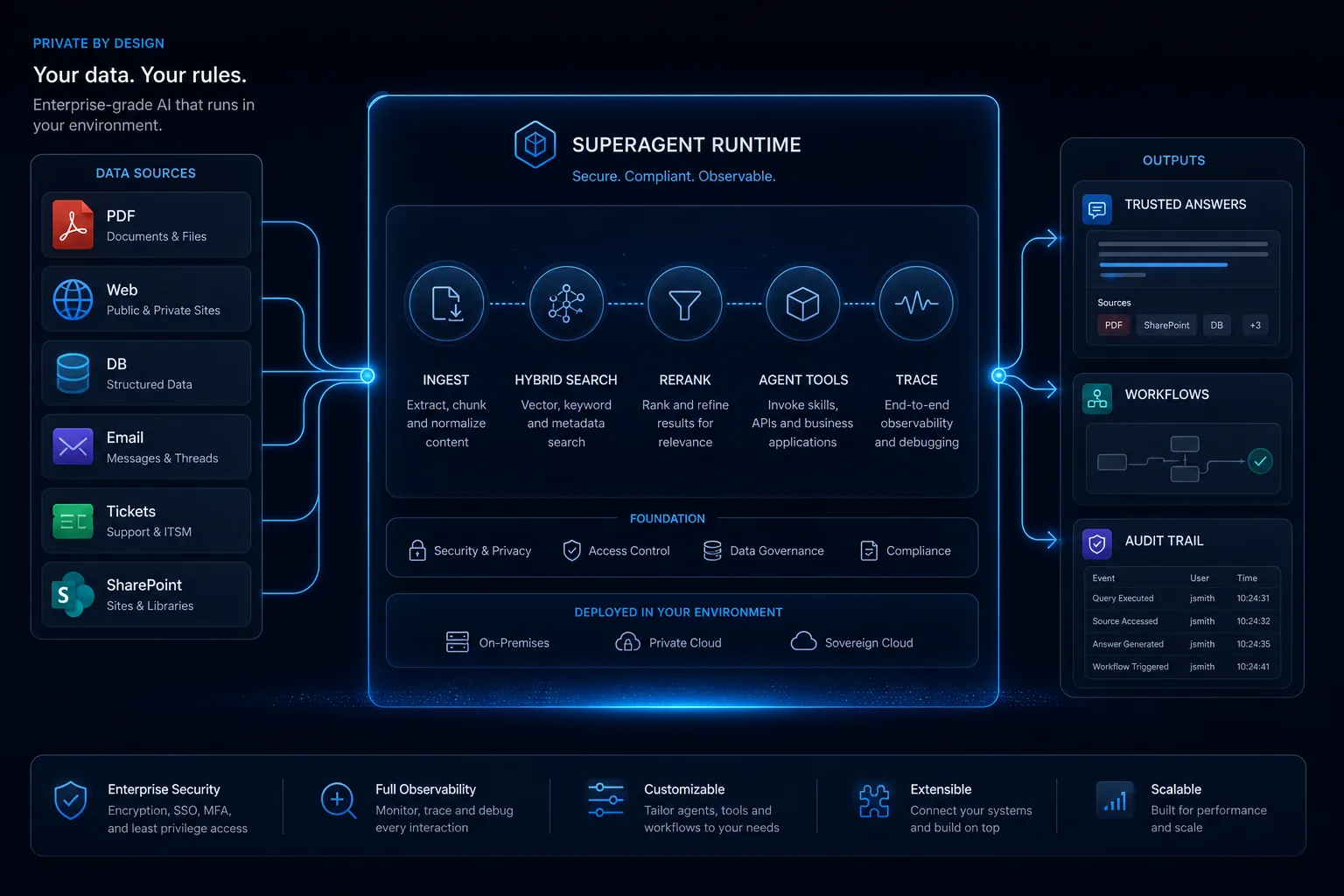
Superagent 深度介绍
Superagent 将分散的企业知识转化为可靠的 AI 工作流,并已在标普 500 企业的生产环境中运行验证。它专为答案需要跨多种来源的场景设计:文档、网页、产品目录、工单、结构化数据库和实时运营数据。
核心优势是完全可控。数据采集、文档解析、索引构建、检索排序、大模型和工具链的每一层都可独立替换和调优,确保企业能按自身需求私有部署并持续优化答案质量。
请求路径

爬取网站,解析 PDF 和 Office,规范化 HTML 表格,用 LLM 给 chunk 增强上下文,并随着源数据变化保持索引新鲜。
组合语义向量检索、关键词检索、RRF 融合、rerank、metadata filter、parent/sibling expansion,让答案来自正确证据。
通过 OpenAI-compatible API 暴露 RAG 和工具型 Agent,支持任务专用模型、结构化工具调用和统一 chat/completions 入口。
把产品、库存、工单、CRM、SQL 或运营数据注入回答链路,而不是只靠静态文档猜答案。
追踪每次检索和生成,比较回答质量,定位召回失败,并持续改进 chunking、ranking、prompt 和工具。
运行在客户可控环境中,模型、向量库、搜索引擎和数据连接器都可以替换。
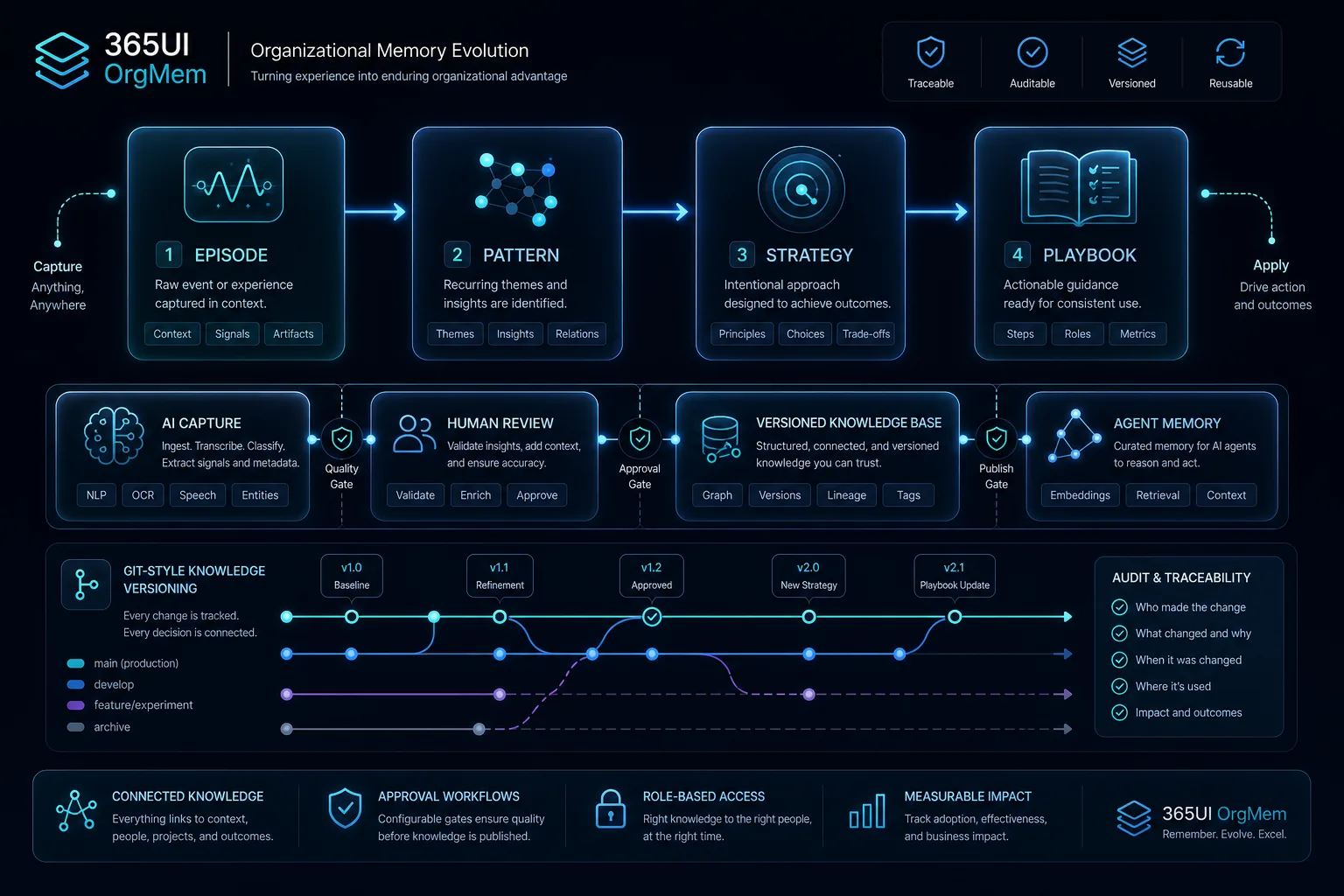
OrgMem 深度介绍
OrgMem 把组织知识、决策历史和 Agent 执行记忆放在同一个可审计系统里。它既是企业知识库,也是 Agent 的长期记忆层:人类保留最终治理权,AI 获得结构化读写和持续学习能力。
记忆演进路径
Episode → Pattern → Strategy → Playbook
失败会被记住,成功会被强化,高频且验证过的经验会晋升为正式组织 know-how。

知识存储在 Markdown + Git 中,不锁定在特定数据库或 SaaS 平台。每一次变更都有记录,支持审计、追溯和分支管理。
AI 持续捕捉和沉淀执行经验,但正式组织知识需经人工审核后方可入库,确保知识库的准确性和可信度。
语义检索与关键词精确匹配融合,配合多级精排和实体增强,兼顾概念理解和术语精确度,适合真实企业知识场景。
不仅是文档搜索。OrgMem 记录执行过程、失败分析、有效策略和团队偏好,让 AI 助手从历史经验中持续学习。
当前任务相关知识即时可用,项目级策略在会话启动时预加载,跨项目知识按需检索,减少无关信息干扰。
通过置信度、使用频率和时效性管理知识有效性;经反复验证的高价值经验自动晋升为正式操作手册。
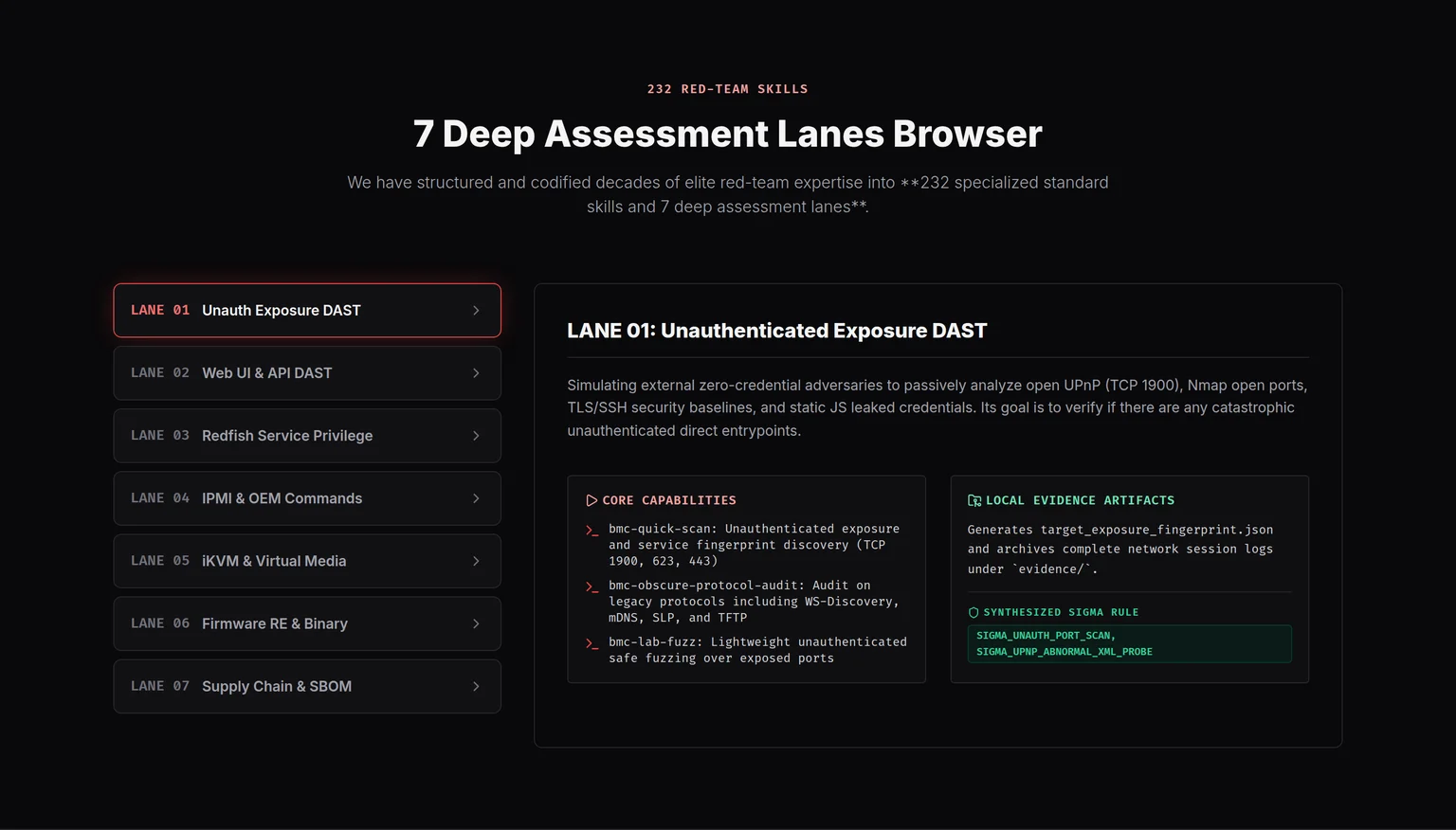
BMC Red-Team Lab · 最新成果
232 个专项 skill 沿 7 条深度评估通道路由——Unauth-DAST、Web UI、Redfish privilege、IPMI / OEM、iKVM、固件 RE、供应链 SBOM 与 OpenBMC / libpldm 协作修复链。多模型 Council 架构:主审查官 Hunter(Claude Opus 4.7 Thinking)与唱反调合规官 Skeptic(GPT-5.5 Extra Reasoning)就每个候选博弈,最终由确定性 Node 代码 Governor 做 Fail-Closed 决策。
所有发现按 Proof Ladder 逐级晋升(静态候选 → deployed daemon 可达 → 实验室复现 → 可利用性),每条攻击 primitive 自动起 paired Sigma 检测规则。OpenBMC libpldm decode_get_types_resp() 报告已经从源码 OOB read 推进到 deployed pldmd 可达、受控 fake MCTP peer-path 证据与 candidate fix,并由 OpenBMC 官方安全团队答复跟进——这就是对位 Mythos 类 AI 0-day 神器的真实闭环。

能力地图
从网页、PDF、Office、邮件、数据库和 API 中采集企业私有知识,统一进入可检索、可追溯的数据层
多路检索融合 + 精排 + 结构化数据注入,确保答案基于准确证据而非猜测
Agent 支持多步骤工具调用、长流程执行、记忆和权限控制,覆盖真实业务场景而不仅是一次性问答
全栈可自托管部署,数据不出企业边界,适合对数据安全有严格要求的团队
内置评测、链路追踪、回滚和版本管理,确保系统可持续运营和持续改进
已在 AI 知识问答、流程自动化、组织记忆、团队协作治理、招聘、消息平台和边缘语音等场景实际交付
Agent-native 架构推到高风险垂直领域:BMC Red-Team Lab 用 232 个 skill + 7 条评估通道 + 多模型 Council 博弈(Hunter / Skeptic / Deterministic Governor)+ Proof Ladder 证据天梯 + paired Sigma 防御规则;OpenBMC `libpldm` 报告已由上游官方安全团队答复跟进
服务方案
选择一个高价值知识领域,交付可评测答案质量的私有 AI 助手。
接入多数据源,配置角色化工作流、审核队列和生产级监控。
将 Superagent 运行时集成到您的产品、门户、客服流程或内部运营系统中。
常见问题
365UI 不是通用聊天账号,而是面向企业私有数据和真实工作流的交付系统。重点在私有部署、混合检索、工具调用、审计 trace、评测闭环和与内部系统集成。
可以。Superagent 的定位就是客户可控环境中的私有 AI 运行时,模型、向量库、搜索引擎和数据连接器都可以按客户基础设施替换。
通常需要一个明确工作流、一批真实数据、一个业务 owner 和一个成功指标。365UI 会先交付可运行、可评测的 pilot,再扩展到多数据源和生产流程。
答案链路会结合语义检索、关键词检索、rerank、metadata filter、结构化数据注入和 evidence trace,让回答基于可追溯证据,而不是只依赖模型自由生成。
适合有大量私有文档、数据库、工单、邮件、产品资料、SOP 或合规内容的团队,尤其是客服知识检索、销售支持、内部政策助手、招聘筛选、报告生成和流程自动化。
OrgMem 不只是存文档。它记录决策历史、执行经验、失败分析、有效策略和 Agent 记忆,并通过人工审核与版本化流程把高价值经验晋升为正式组织知识。
可以,BMC Red-Team Lab 就是样本:232 个专项 skill 沿 7 条评估通道路由,多模型 Council 博弈(主审查官 Claude Opus 4.7 Thinking、唱反调合规官 GPT-5.5 Extra Reasoning、最终由确定性 Node 代码 Governor Fail-Closed 决策),所有发现按 Proof Ladder 从静态候选逐级晋升到 deployed daemon 可达与可利用性证据,每条攻击 primitive 自动起 paired Sigma 检测规则,OpenBMC libpldm 报告已被官方安全团队答复跟进。对位 Mythos 类 AI 全自动 0-day 神器,靠的是 24/7 自建红队闭环、不依赖外部 0-day broker。
只需要一个工作流场景、一份数据和一个成功指标。我们先交付可运行的 Pilot,再扩展为完整平台。